

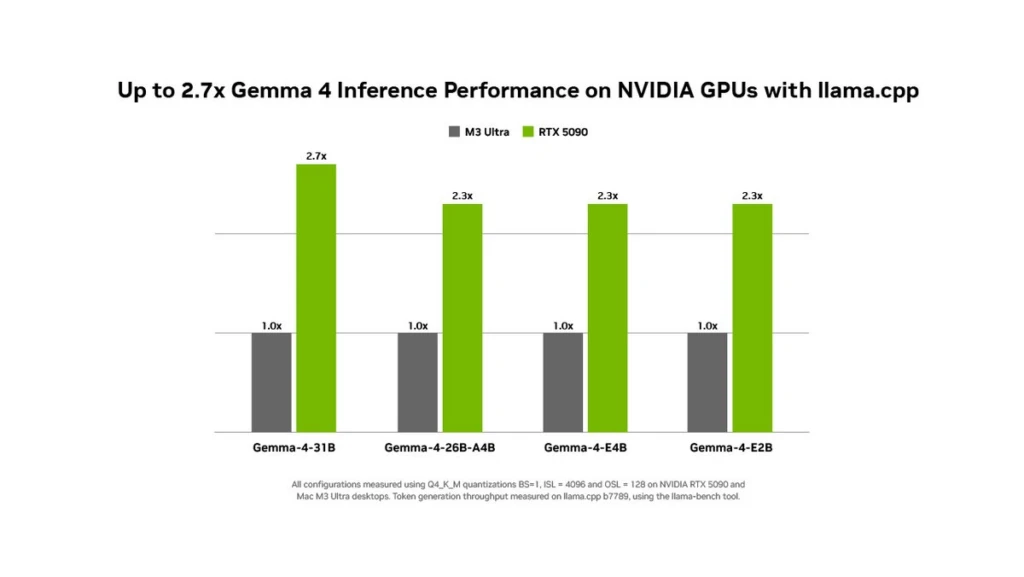
Nvidia officially benchmarked the RTX 5090 against Apple’s M3 Ultra and claimed 2.7x faster speeds. One problem. We ran the numbers and the gap looks very different.The topic was local AI performance and I wanted to compare the RTX 5090 vs M5 Ultra as well.
The graphic looked quite simple: RTX 5090 as a green bar, M3 Ultra as a gray bar, with “2.7x” written on top. The message was clear: “We are faster than Mac Studio.”
But wait. This graphic is a marketing material prepared by Nvidia itself. Which model did they test, which conditions did they choose, what did they deliberately leave out? And more importantly: if we ran the same test with the M5 Ultra, whose release date is just around the corner, how would the results change?
What Did Nvidia Test, and How Did They Test It?
The Apple hardware Nvidia used in their test was the Mac Studio M3 Ultra. What was being measured is simple: how many tokens does it generate per second? This metric is genuinely important for those running local AI models. The higher this number, the faster the model responds.
The test conditions were as follows:
- Tool: llama.cpp b7789
- Models: Google’s Gemma 4 series: E2B, E4B, 26B-A4B and 31B
- Quantization: Q4_K_M
- Metric: Token generation throughput (tokens/second)
The results? RTX 5090 came out 2.3x to 2.7x faster against the M3 Ultra. The biggest gap was on the 31B model, a full 2.7x.
That sounds crushing. But before diving into the numbers, let’s look at what these two pieces of hardware actually have under the hood.
The Technical Profile of the M3 Ultra
In the Apple Silicon world, Ultra chips are created by connecting two dies of the Max chip together. Apple uses a proprietary packaging architecture called UltraFusion for this. This technology allows two separate Max chips to be perceived by software as a single massive chip. The M3 Ultra was built this way and was Apple’s most powerful chip at the time.
| Spec | M3 Ultra | RTX 5090 |
| GPU Core | 80 cores | 21,760 CUDA cores |
| Memory | 96GB Unified(min) | 32GB VRAM |
| Memory Bandwidth | 819 GB/s | 1,792 GB/s |
| Power Consumption | 100W-180W* | 575W |
| Price | $4,000 | $3,500+ (market price) |
There is something worth noting here: the RTX 5090’s memory bandwidth is approximately 2.2 times that of the M3 Ultra. Since token generation speed is directly related to memory bandwidth, this gap reflects almost directly into the 2.3-2.7x result. So the number Nvidia got is actually exactly the expected outcome.
No surprise there. So now let’s ask the real question: how does this picture change when the M5 Ultra enters the scene?


The Architecture and Expected Specs of the M5 Ultra
The M5 Ultra has not been released yet. According to Mark Gurman from Bloomberg, it is expected to be announced at WWDC in June 2026. But since the M5 Max is already out, we have a very solid projection foundation to work from.
The most significant architectural innovation coming with the M5 series is Fusion Architecture. In the M5 Pro and Max, the CPU and GPU are no longer on the same monolithic die but on separate tiles. This both improves production yield and thermal management. Meaning you can push the CPU to its limits without sacrificing GPU performance.
There is also a critical change in M5’s GPU architecture: a Neural Accelerator has been placed inside each GPU core. In the M4, these computations were handled in a separate unit from the GPU cores. In the M5, each core handles its own AI operations internally. Apple describes this as “4x peak GPU compute for AI.”
Projecting all of this onto the M5 Ultra, the expected picture looks like this:
| Spec | M3 Ultra (tested) | M5 Max (current) | M5 Ultra (expected) |
| CPU Cores | 32 | 18 | 36 |
| GPU Cores | 80 | 40 | 80 |
| Memory Bandwidth | 819 GB/s | 614 GB/s | 1,100-1,228 GB/s |
| Max Unified Memory | 96 GB(min) | 128GB | 128Gb(min) |
| Neural Engine | M3 gen | M5 gen | M5 gen x2 |
| Manufacturing Process | 3nm | 3nm 2nd gen | 3nm 2nd gen |
Memory bandwidth is the most critical number here. The M3 Ultra’s 819 GB/s was at a 45.7% ratio against the RTX 5090’s 1,792 GB/s. The M5 Ultra’s expected 1,100-1,228 GB/s brings this ratio up to 61-68%. This means the gap is starting to close.
The Rumor: Could It Be a Single Die?
This is the most interesting part of the article.
As we mentioned above, Apple builds the M1, M2 and M3 Ultra by connecting two Max dies with a UltraFusion connector. However, in the M4 series, Apple did not include this connector in the M4 Max, which is exactly why the M4 Ultra never came out.
When the M5 Max launched, only M5 Max and M5 Ultra references were found in OS beta code, with no separate M5 Pro reference. Vadim Yuryev from the Max Tech YouTube channel explained this with an interesting theory: Apple may now be building the M5 Pro and M5 Max on a single chip design. With TSMC’s SoIC-mH packaging combined with 2.5D chip technology, Pro and Max are now produced from the same die, differentiated only by the number of GPU tiles.
The implication of this theory for the M5 Ultra is striking: if there is no UltraFusion connector and the chip design has already moved to a modular tile structure, the M5 Ultra could be produced as a single monolithic die rather than a fusion of two separate Max dies.
What does this mean? Using a single large die instead of connecting two separate dies with an interposer:
- Reduces inter-die latency to zero
- Allows memory bandwidth to be used more efficiently
- Makes a much larger unified memory pool possible, with some leaks mentioning 512GB or even 1TB
If this scenario plays out, circling back to what we said at the beginning: the M5 Ultra’s memory bandwidth could exceed the expected 1,228 GB/s. The gap with the RTX 5090 narrows even further. And in the 70B+ model scenario, the M5 Ultra would sit as the undisputed leader not just in speed but in capacity as well.
Of course all of this is still at the level of leaks and theory. We are waiting for an official announcement from Apple before WWDC 2026.
What Would Happen If We Ran the Same Test with the M5 Ultra?
Let’s look at what would happen if we ran this test under normal expectations.
Token generation speed scales linearly with memory bandwidth. This is a simple but powerful forecasting tool. Most of the 2.7x gap between the M3 Ultra and RTX 5090 was already coming from the bandwidth difference.
The estimated table for how this gap would change with the M5 Ultra:
| Model | RTX 5090 | M3 Ultra (actual) | M5 Ultra (projection) |
| Gemma-4-31B | 2.7x | 1.0x | 1.7-2.0x |
| Gemma-4-26B-A4B | 2.3x | 1.0x | 1.5-1.7x |
| Gemma-4-E4B | 2.3x | 1.0x | 1.5-1.7x |
| Gemma-4-E2B | 2.3x | 1.0x | 1.5-1.7x |
So the “2.7x faster” claim would likely come down to 1.7-2.0x when it meets the M5 Ultra. The RTX 5090 is still ahead, but we can say it is less ahead than before.
What Nvidia Left Out: Model Size
As model sizes increase, the required technology grows with them. The largest model Nvidia chose was the 31B parameter Gemma-4-31B. This is not a coincidence. The 31B model takes up approximately 19-20GB in memory with Q4_K_M quantization, fitting perfectly into the RTX 5090’s 32GB VRAM. The model runs entirely on the GPU, delivering maximum speed.
So what happens with a 70B model?
On the RTX 5090, the 70B model does not fit in VRAM. Roughly half of it gets pushed to system RAM. This causes constant data transfer between the GPU and CPU, and the speed drops dramatically, with some tests showing up to 10x slowdowns. On the M5 Ultra, thanks to 256GB of unified memory, the 70B model runs entirely on chip without any issues.
| Scenario | RTX 5090 | M5 Ultra (expected) |
| 31B model | Fits in VRAM, fast | Fast |
| 70B model | Half pushed to CPU, slow | Fully on chip |
| 120B model | Not good | Works |
| Power consumption | 575W | 100W-180W (expected) |
This is where the real competitive advantage emerges. The RTX 5090 has a clear speed advantage for models under the 32GB limit. But once you cross that threshold, the table flips entirely.
Conclusion
Nvidia’s graphic is not technically wrong. Under the conditions it set, with the model size it chose and the tool it selected, the RTX 5090 is genuinely 2.7x faster.
However, the graph doesn’t tell us everything. You need to consider things like the difference being roughly halved with the M5 Ultra, the situation completely reversing for models priced above 70 billion, all of this happening at around 100W-180W instead of 575W, and the RTX 5090’s card price alone being over $3500. I also want to point out that the card’s current price is as of the date of publication and may change in the future.
We will see the real benchmarks when the M5 Ultra launches. But looking at the data we have, the shelf life of Nvidia’s “2.7x” claim appears to run until WWDC 2026.
Click here for my other articles about Apple.

